系統使用說明
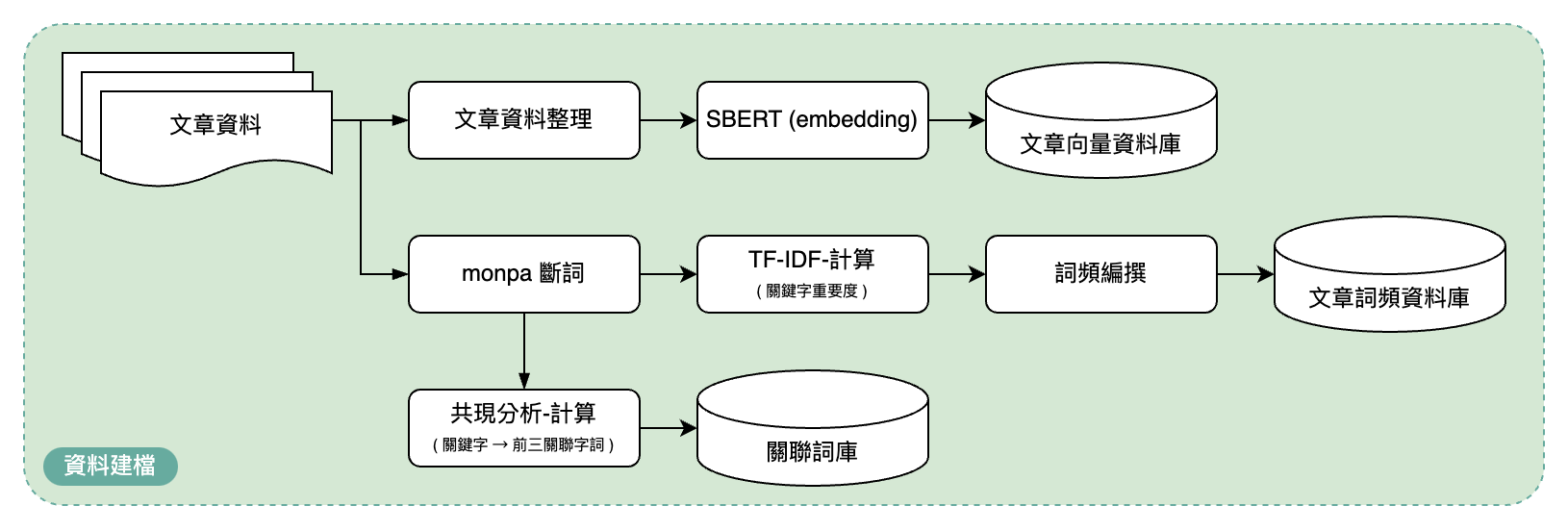
知識文本資料前處理
取得文章的標題、內文與連結後會以純文本的形式儲存至 mongoDB 的文章文本資料庫進行管理,為了滿足 RAG 的文章搜尋需求,標題與內文會合併成索引文本,索引文本會在透過 Sentence-BERT 的 paraphrase-multilingual-mpnet-base-v2 多語言模型轉換成固定長度的向量並儲存至文章向量資料庫。
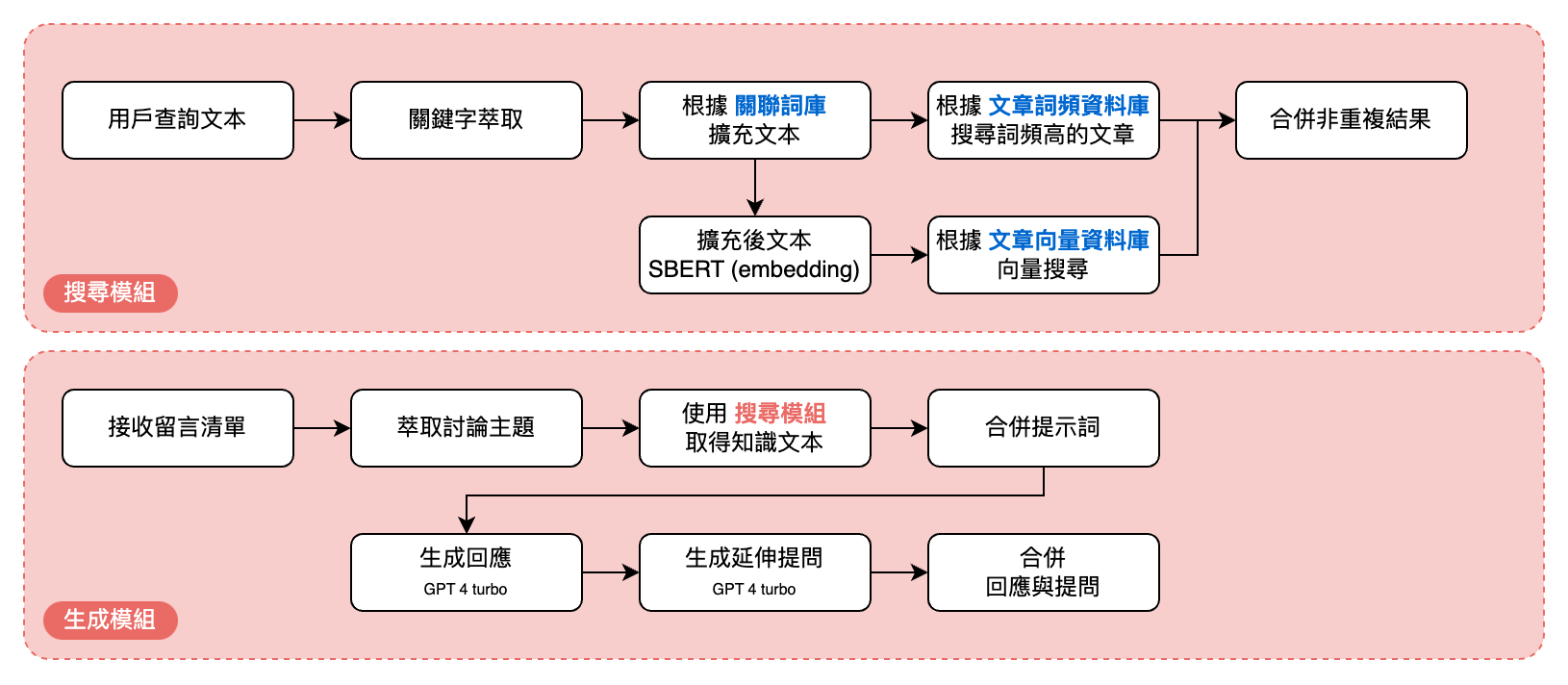
模組建立
搜索架構
融合BM25(詞頻)、TF-IDF、共現分析 與 SBERT Embeding 技術打造的資源推薦算法,透過使用者輸入的關鍵字,進行科普資源搜尋。回應架構
基於RAG 與鏈式提示策略設計,使用大型語言模型(GPT-4 Turbo)生成適切的回應與延伸提問。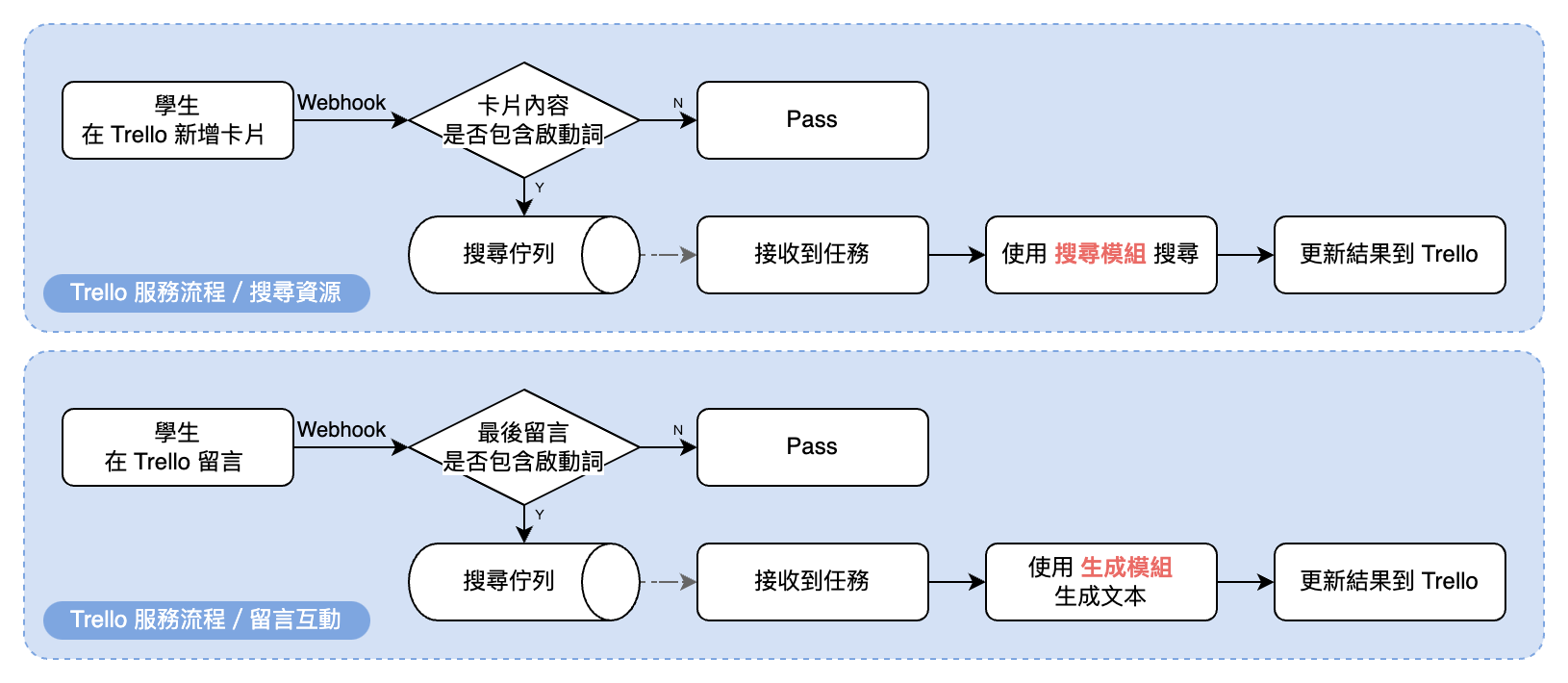
Trello 資料建立流程
提示詞列表
| role | prompt |
|---|---|
| system | #zh_tw 你是一位使用繁體中文的自然科學中學老師,正在跟剛接觸研究領域的學生交談,首先學生正在研究 研究主題,而你需要幫助學生瞭解相關知識,因此你需要生成回答並追問學生讓學生回答以促進學生對 研究主題 深度思考。輸出的文本需要基於 Markdown 語法。 |
| user | *聊天文本(舊~新)* |
回應模組資料前處理
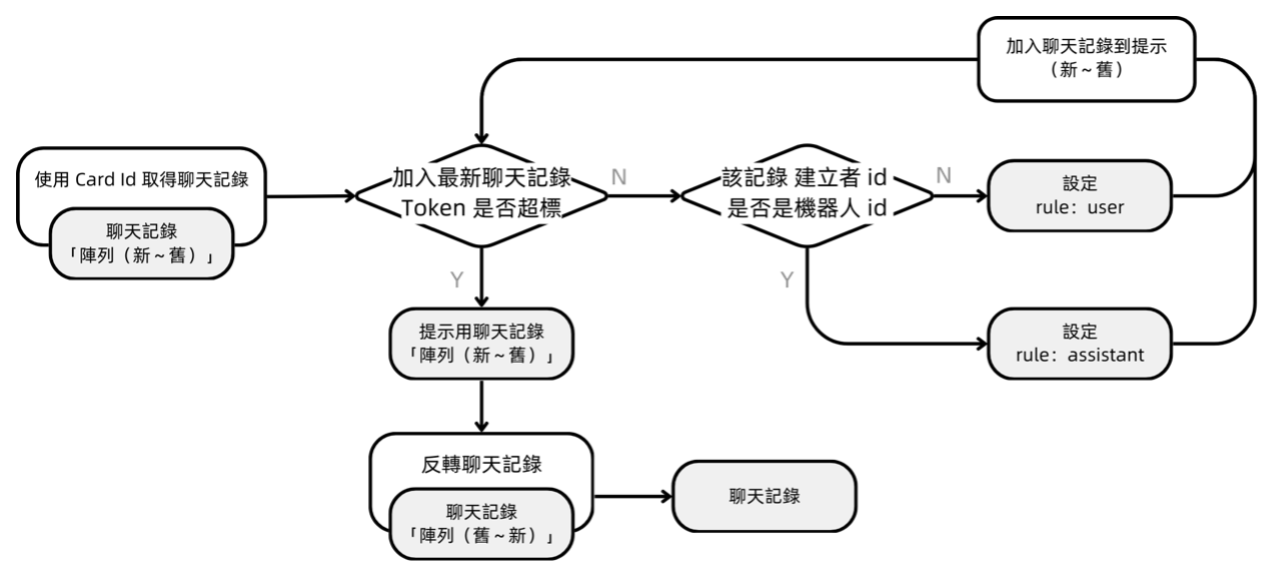
聊天文本處理
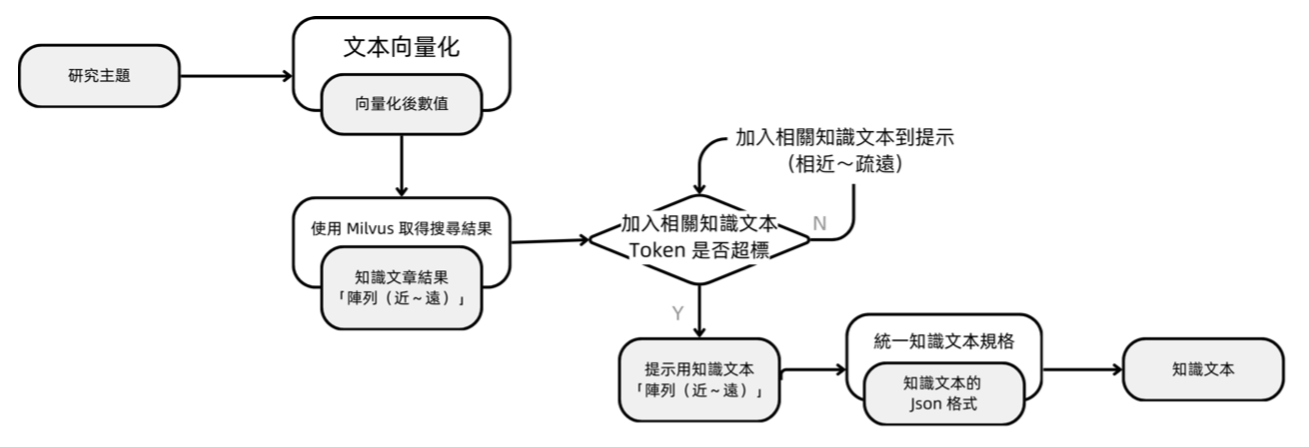
知識文本處理
搜尋模組
使用自然語言技術建構自主學習資源推薦系統
融合 BM25(詞頻)、TF-IDF、SBERT Embeding 技術打造的資源推薦算法,透過使用者輸入的關鍵字,進行科普資源搜尋。